<!ELEMENT ElementName Type>
The name of the element determines the name of the tag(s) used to mark up the element in a document and corresponds to ElementName in the element declaration. This name must be unique within the context of a DTD. The type of the element is specified in Type; XML supports four different types of elements, which are determined by the content contained within the element:
-
Empty The element doesn't contain any content (it can still contain attributes).
-
Element-only The element only contains child elements.
-
Mixed The element contains a combination of child elements and character data.
-
Any The element contains any content allowed by the DTD.
The name of an element must not contain the ampersand character (&) or begin with the sequence of letters X, M, and L in any case combination (XML, xml, XmL, and so on).
The next few sections explore the different element types in more detail.
Peeking Inside Empty Elements
An empty element is an element that doesn't contain any element content. An empty element can still contain information, but it must do so using attributes. Empty elements are declared using the following form:
<!ELEMENT ElementName EMPTY>
Following is an example of declaring an empty element using this form:
<!ELEMENT clothing EMPTY>
After an empty element is defined in a DTD, you can use it in a document in one of two ways:
-
With a start tag/end tag pair
-
With an empty tag
Following is an example of an empty element defined using a start tag/end tag pair:
<clothing></clothing>
Notice that no content appears between the tags; if any content did appear, even a single space, the document would be invalid. A more concise approach to defining empty elements is to use an empty tag. Following is an example of using an empty tag to define an empty element:
<clothing />
As you can see, an empty tag is somewhat of a combination of a start tag and end tag. In addition to being more concise, empty tags help to make it clear in a document that an element is empty and therefore can't contain content. Remember that empty elements can still contain information in attributes. Following is an example of how you might use a few attributes with an empty element:
<clothing type="t-shirt" color="navy" size="xl" />
Housing Children with Element-Only Elements
An element-only element contains nothing but child elements. In other words, no text content is stored within an element-only element. An element is declared element-only by simply listing the child elements that can appear within the element, which is known as the element's content model. Following is the form expected for declaring an element's content model:
<!ELEMENT ElementName ContentModel>
The content model is specified using a combination of special element declaration symbols and child element names. The symbols describe the relationship between child elements and the container element. Within the content model, child elements are grouped into sequences or choice groups using parentheses (()). A sequence of child elements indicates the order of the elements, whereas a choice group indicates alternate possibilities for how the elements are used. Child elements within a sequence are separated by commas (,), whereas elements in a choice group are separated by pipes (|). Following are the different element declaration symbols used to establish the content model of elements:
-
Parentheses (
()) Encloses a sequence or choice group of child elements -
Comma (
,) Separates the items in a sequence, which establishes the order in which they must appear -
Pipe (
|) Separates the items in a choice group of alternatives -
No symbol Indicates that a child element must appear exactly once
-
Question mark (
?) Indicates that a child element must appear exactly once or not at all -
Plus sign (
+) Indicates that a child element must appear at least once -
Asterisk (
*) Indicates that a child element can appear any number of times
Although I could use several paragraphs to try and explain these element declaration symbols, I think an example is much more explanatory. Following is the declaration for an element named resume that might be used in a resume markup language:
<!ELEMENT resume (intro, (education | experience+)+, hobbies?, references*)>
The resume element is pretty interesting because it demonstrates the usage of every element declaration symbol. The resume element is element-only, which is evident by the fact that it contains only child elements. The first child element is intro, which must appear exactly once within the resume element; this is because no symbols are used with it. The education or experience elements must then appear at least once, which is indicated by the plus sign just outside of the parentheses. Within the parentheses, the education element must appear exactly once, whereas the experience element must appear at least once but can also appear multiple times. The idea is to allow you to list part of your education followed by any relevant work experience; you may have worked multiple jobs following a single block of education. The hobby element can appear exactly once or not at all; all of your hobbies must be listed within a single hobby element. Finally, the references element can appear any number of times.
To get a practical feel for how element-only elements affect XML documents in the real world, take a look at the following line of code from the DTD for the RSS language:
<!ELEMENT item (title | link | description)*>
RSS is an XML-based language that is used to syndicate web sites so that applications and other web sites can obtain brief descriptions of new articles and other content. For example, Sports Illustrated (http://sportsillustrated.cnn.com/) offers RSS news feeds for all major sports. Other web sites can tap into these feeds or you can use an RSS aggregator application such as FeedDemon(http://www.feeddemon.com/), which allows you to view news feeds much like you view email in an email client.
Anyway, getting back to the RSS DTD, the previous line of code reveals that the item element can contain any combination of title, link, or description elements as long as there is no more than one of each. To see how this DTD translates into real XML code, check out the following excerpt from a real Sports Illustrated NFL news feed:
<item> <title>Titans' trio of young WRs showing promise</title> <link>http://sportsillustrated.cnn.com/rssclick/2005/football/nfl/06/22/ bc.fbn.titans.receivers.ap/index.html?section=si_nfl</link> <description>Read full story for latest details.</description> </item>
To view the XML code for a Sports Illustrated news feed for yourself, visit the main Sports Illustrated page, scroll down to the bottom, and click the small XML logo. A list of news feeds appearsclick any of them to open the RSS document containing the feed data.
As this code reveals, the item element contains exactly one each of title, link, and description elements. To see how this code affects a real web page, check out the syndicated NFL news feed on my web site in Figure 3.1.
Figure 3.1. The example syndicated NFL news feed is visible on my web site.
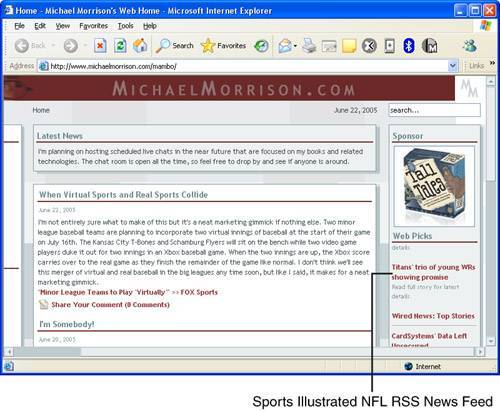
The figure reveals how the Tennessee Titans news story shown in the previous RSS code is syndicated and visible as an RSS news feed on my web site.
In the next section you see how the individual RSS elements mentioned here are defined in the RSS DTD. You also find out more details about how to syndicate news feeds and create your own in Syndicating The Web With RSS News Feeds, "Syndicating the Web with RSS News Feeds."
Combining Content and Children with Mixed Elements
Mixed elements are elements that contain both character data (text) and child elements. The simplest mixed element is also known as a text-only element because it contains only character data. Text-only elements are declared using the following form:
<!ELEMENT ElementName (#PCDATA)>
The content model for text-only elements consists solely of the symbol #PCDATA contained within parentheses, which indicates that an element contains Parsed Character DATA. Following is an example of a simple text-only element declaration:
<!ELEMENT hobbies (#PCDATA)>
The word "parsed" in Parsed Character DATA (PCDATA) refers to the fact that PCDATA within a document is processed (parsed) by an XML application. Most of the text content in an XML document is considered PCDATA, including character entities for example. The parsing process involves stripping out extraneous whitespace and, in the case of character entities, replacing entities with the appropriate text. The alternative to PCDATA is CDATA (Character DATA), which is text that isn't processed by an XML application. Later you learn when it is useful to include CDATA in a document.
This element might be used to mark up a list of hobbies in an XML document that helps to describe you to other people. Following is an example of how you might define the hobbies element in a document:
<hobbies>juggling, unicycling, tight-rope walking</hobbies>
Speaking of examples, the following code shows the title, link, and description elements from the RSS DTD that you learned about in the previous section:
<!ELEMENT title (#PCDATA)> <!ELEMENT link (#PCDATA)> <!ELEMENT description (#PCDATA)>
As you can see, these elements are all defined as text-only elements, which makes sense given the sample RSS data you saw in the previous section.
In reality, a text-only element is just a mixed element that doesn't contain any child elements. Mixed elements that contain both text data and child elements are declared very much like element-only elements, with the addition of a few subtle requirements. More specifically, the content model for a mixed element must contain a repeating choice list of the following form:
<!ELEMENT ElementName (#PCDATA | ElementList)*>
If this looks a little confusing at first, don't worry. Let's break it down. The symbol #PCDATA at the start of the choice list indicates that the mixed element can contain character data. The remainder of the choice list contains child elements, and resembles a regular element-only content model. Additional #PCDATA symbols may be interspersed throughout the content model to indicate that character data appears throughout the child elements. An asterisk (*) must appear at the end of the content model's choice list to indicate that the entire choice group is optionalthis is a requirement of mixed elements. Also, although a mixed element declaration constrains the type of child elements allowed, it doesn't constrain the order of the elements or the number of times they may appear.
In the content model for a mixed element, the character data (#PCDATA) must always be specified first in the choice group, and the choice group itself must be declared as repeating by following it with an asterisk (*).
Although mixed elements provide a considerable amount of flexibility, they lack the structure of element-only elements. So, with the exception of text-only elements, you're better off using element-only elements instead of mixed elements whenever possible; you can often get the equivalent of a mixed element by declaring attributes on a text-only element.
Keeping Your Options Open with Any Elements
The any element is the most flexible element of all because it has virtually no structure. The any element is declared using the symbol ANY, and earns its name by being able to contain any declared element types, character data, or a mixture of both. You can think of the any element as a mixed element with a wide-open content model. Following is the form used to declare an any element:
<!ELEMENT ElementName ANY>
Not surprisingly, the lack of structure associated with the any element makes it something you should avoid at all costs in a production DTD. I mention a production (completed) DTD because the any element is typically used only during the development of a DTD for testing purposes.