There are some key advantages to a RAID 1 solution. First, it is cheap, as only two hard disks are required to provide fault tolerance. Second, no additional software is required for establishing RAID 1, as modern network operating systems have built-in support for it. RAID levels using striping are often incapable of including a boot or system partition in fault-tolerant solutions. Finally, RAID 1 offers load balancing over multiple disks, which increases read performance over that of a single disk. Write performance however is not improved.
Because of its advantages, RAID 1 is well suited as an entry-level RAID solution, but it has a few significant shortcomings that exclude its use in many environments. It has limited storage capacitytwo 100GB hard drives only provide 100GB of storage space. Organizations with large data storage needs can exceed a mirrored solutions capacity in very short order. RAID 1 also has a single point of failure, the hard disk controller. If it were to fail, the data would be inaccessible on either drive. Figure 3 shows an example of RAID 1 disk mirroring.
Figure 3 RAID 1 disk mirroring.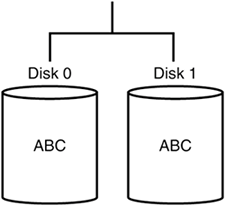
An extension of RAID 1 is disk duplexing. Disk duplexing is the same as mirroring with the exception of one key detail: It places the hard disks on separate hard disk controllers, eliminating the single point of failure.