XPath is a very important XML technology in that it provides a flexible means of addressing XML document parts. Any time you need to reference a portion of an XML document, such as with XSLT, you ultimately must rely on XPath. The XPath language is not based upon XML, but it is somewhat familiar nonetheless because it relies on a path notation that is commonly used in computer file systems. In fact, the name XPath stems from the fact that the path notation used to address XML documents is similar to path names used in file systems to describe the locations of files. Not surprisingly, the syntax used by XPath is extremely concise because it is designed for use in URIs and XML attribute values.
Similar to other XML technologies, XPath operates under the notion that a document consists of a tree of nodes. XPath defines different types of nodes that are used to describe nodes that appear within a tree of XML content. There is always a single root node that serves as the root of an XPath tree, and that appears as the first node in the tree. Every element in a document has a corresponding element node that appears in the tree under the root node. Within an element node there are other types of nodes that correspond to the element's content. Element nodes may have a unique identifier associated with them that is used to reference the node with XPath. Figure 22.1 shows the relationship between different kinds of nodes in an XPath tree.
Figure 22.1. XPath is based upon the notion of an XML document consisting of a hierarchical tree of nodes.
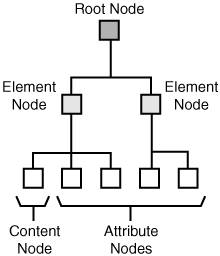
Nodes within an XML document can generally be broken down into element nodes, attribute nodes, and text nodes. Some nodes have names, in which case the name can consist of an optional namespace URI and a local name; a name that includes a namespace prefix is known as an expanded name. Following is an example of an expanded element name:
<xsl:value-of select="."/>
In this example, the local name is value-of and the namespace prefix is xsl. If you were to declare the XSL namespace as the default namespace for a document, you could get away with dropping the namespace prefix part of the expanded name, in which case the name becomes this:
<value-of select="."/>
If you declare more than one namespace in a document, you will have to use expanded names for at least some of the elements and attributes. It's generally a good idea to use them for all elements and attributes in this situation just to make the code clearer and eliminate the risk of name clashes.
Getting back to node types in XPath, following are the different types of nodes that can appear in an XPath tree:
-
Root node
-
Element nodes
-
Text nodes
-
Attribute nodes
-
Namespace nodes
-
Processing instruction nodes
-
Comment nodes
You should have a pretty good feel for these node types, considering that you've learned enough about XML and have dealt with each type of node. The root node in XPath serves the same role as it does in the structure of a document: it serves as the root of an XPath tree and appears as the first node in the tree. Every element in a document has a corresponding element node that appears in the tree under the root node. Within an element node appear all of the other types of nodes that correspond to the element's content. Element nodes may have a unique identifier associated with them, which is useful when referencing the node with XPath.
The point of all this naming and referencing of nodes is to provide a means of traversing an XML document to arrive at a given node. This traversal is accomplished using expressions, which you learned a little about back in Access Your ITunes Music Library Via XML, "Access Your iTunes Music Library via XML." You use XPath to build expressions, which are typically used in the context of some other operation, such as a document transformation. Upon being processed and evaluated, XPath expressions result in a data object of one of the following types:
-
Node set A collection of nodes
-
String A text string
-
Boolean A true/false value
-
Number A floating-point number
Similar to a database query, the data object resulting from an XPath expression can then be used as the basis for some other process, such as an XSLT transformation. For example, you might create an XPath expression that results in a node set that is transformed by an XSLT template. On the other hand, you can also use XPath with XLink, where a node result of an expression could form the basis of a linked document.
To learn more about the formal XPath specification, visit the XPath section of the W3C web site at http://www.w3.org/TR/xpath.