Loading an XML Document
It turns out that perhaps the trickiest part of DOM programming with JavaScript is initially loading the document into memory so that you can access it programmatically. No one has settled on a standard approach for initially loading an XML document, so we're unfortunately left dealing with different approaches for different browsers. Following is the code to load an XML document into Internet Explorer:
var xmlDoc;
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.load("condos.xml");
As this code reveals, you must first create an ActiveX object (Microsoft.XML.DOM) and then call the load() method on the object to load a specific XML document. Okay, that technique is pretty straightforward, right? Problem is, it won't work in Firefox. Following is the equivalent code for loading an XML document in Firefox:
xmlDoc = document.implementation.createDocument("", "", null);
xmlDoc.load("condos.xml");
This code is obviously different from the Internet Explorer version, or at least the creation of the xmlDoc object is different. If you want your pages to work on both major browsers, and I'm sure you do, you'll need to include code to conditionally load the XML document differently based on the browser. Here's the code to pull off this feat:
if (window.ActiveXObject) {
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.load("condos.xml");
}
else {
xmlDoc = document.implementation.createDocument("", "", null);
xmlDoc.load("condos.xml");
}
This code takes advantage of the fact that Firefox doesn't have an ActiveXObject in the window object that represents the browser. You can therefore use the presence of this object as the basis for using the Internet Explorer approach to loading an XML document. If the object isn't there, the Firefox approach is used.
When the XML document is loaded, you can move on to processing the XML data. However, there is one more browser inconsistency to deal with. The inconsistency has to do with how the two major browsers load XML documents. You will typically create a JavaScript function that processes XML data, and you'll likely want this function to get called right after loading the documents. Following is the code to handle calling a function named printRootNode() upon loading the XML document condos.xml:
if (window.ActiveXObject) {
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.load("condos.xml");
printRootNode();
}
else {
xmlDoc = document.implementation.createDocument("", "", null);
xmlDoc.load("condos.xml");
xmlDoc.onload = printRootNode;
}
This is basically the same code you just saw with a couple of extra lines that call the printRootNode() function a bit differently for each browser. You now have the framework for an HTML page that can load an XML document and call a JavaScript function to get busy processing the document data.
Traversing the DOM Tree
When you have the xmlDoc variable set with the newly loaded XML document, you'll likely want to call a function to start processing the document. In the previous code a function named printRootNode() is called presumably to print the root node of the document. This function is actually just the starting point for printing all of the nodes in the document. Let's look at a script that prints out the names of all of the nodes in the document tree. Listing 16.3 contains the code for a complete web page containing such a script.
Listing 16.3. An HTML Page That Prints All of the Nodes in an XML Document
1: <html>
2: <head>
3: <title>Condominium List</title>
4: <script type="text/javascript">
5: var xmlDoc;
6: function loadXMLDoc() {
7: // XML loader for IE
8: if (window.ActiveXObject) {
9: xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
10: xmlDoc.load("condos.xml");
11: printRootNode();
12: }
13: // XML loader for other browsers
14: else {
15: xmlDoc = document.implementation.createDocument("", "", null);
16: xmlDoc.load("condos.xml");
17: xmlDoc.onload = printRootNode;
18: }
19: }
20:
21: function printRootNode() {
22: printNode(xmlDoc);
23: }
24:
25: function printNode(node) {
26: document.write("<span style='font-weight:bold'>Node name: " +
27: node.nodeName + "</span><br />\n");
28: if (node.nodeValue != null)
29: document.write("Node value: " + node.nodeValue + "<br />\n");
30:
31: for (var i = 0; i < node.childNodes.length; i++)
32: printNode(node.childNodes[i]);
33: }
34: </script>
35: </head>
36:
37: <body onload="loadXMLDoc()">
38: </body>
39: </html>
Let's look at this script in detail. First off, notice that virtually all of the script code is located in functions in the head of the document, which means that it doesn't automatically get executed. However, the loadXMLDoc() function gets called in the <body> tag thanks to the onload attribute (line 37). This is all it takes to get the code started processing the XML document.
When you include JavaScript code on a page, any code that's not inside a function will be executed as soon as the browser interprets it. Code placed in a function is only executed when the function is called.
The loadXMLDoc() handles the XML document loading task you learned about earlier and then calls the printRootNode() function to start printing the nodes (lines 11 and 17). The printRootNode() function is really just a helper function used to start printing the nodes (lines 21 through 23). It is necessary because the real function that prints the nodes, printNode(), requires an attribute but there is no good way to pass along an attribute in the Firefox version of the load routine (line 17). So, you have to print the root node using the printRootNode() function, and from there on the printNode() function takes over.
Most scripts that interact with an entire XML document tree start at the root node and work their way down the tree, as shown in this example.
The rest of the code inside the script tag is inside the printNode() function, and is executed when the printNode() function is called by printRootNode(). As you know, a document node provides all of the methods of the Node interface as well as those specific to the document interface. The printNode() function will work with any node, including a document node; it is called and passed the xmlDoc variable as its argument to print the root node.
You may be wondering exactly how the printNode() can print an entire document tree when it is only called and passed the root node. The answer has to do with a common programming technique called recursion. Recursion is to tree-like data structures what loops are to list data structures. When you want to process a number of similar things that are in a list, you simply process them one at a time until you've processed all of the items in that list. Recursion is a bit more complex. When you're dealing with tree-like data structures, you have to work your way down each branch in the tree until you reach the end.
Let's look at an example not associated with the DOM first. When you want to find a file on your computer's hard drive manually, and you have no idea where it is located, the fastest way to find it is to recursively search all of the directories on the hard drive. The process goes something like this (starting at the root directory):
|
1.
|
Is the file in this directory? If so, we're finished.
|
|
2.
|
If not, does this directory contain any subdirectories? If not, skip to step 4.
|
|
3.
|
If there are subdirectories, move to the first subdirectory and go back to step 1.
|
|
4.
|
Move up one directory. Move to the next subdirectory in this directory, and skip to step 1. If there are no additional subdirectories in this directory, repeat this step.
|
That's one recursive algorithm. The most important thing to understand about recursion is that all of the items being processed recursively must be similar enough to be processed in the same way.
This helps to explain why all of the interfaces in the DOM are extensions of the basic Node interface. You can write one recursive function that will process all of the nodes in a DOM tree using the methods that they have in common. printNode() is one such function
First, let's examine the function declaration. You've already seen a few functions, but let's back up and clarify how functions work in JavaScript. In JavaScript, you indicate that you're creating a function by using the function keyword. The name of the function is supplied next, followed by the list of arguments accepted by the function. The name of this function is printNode(), and it accepts one argument, which is given the name node. This argument is intended to be a node that's part of a DOM tree. Within the function, you can use the name argument to refer to the node that is passed into the function.
In the body of the function, the first thing that happens is the nodeName property of the node currently being processed is printed (lines 26 and 27). If a node value exists, it is printed next (lines 28 and 29). Then, the function loops over the children of the node currently being processed and calls the printNode() function on each of the children (lines 31 and 32). This is where the recursion comes in. The same function, printNode(), is called repeatedly to process every node in the tree. Figure 16.3 contains this page, as viewed in Internet Explorer.
Figure 16.3. The output of a function that prints the names and values of all of the nodes in a DOM tree.
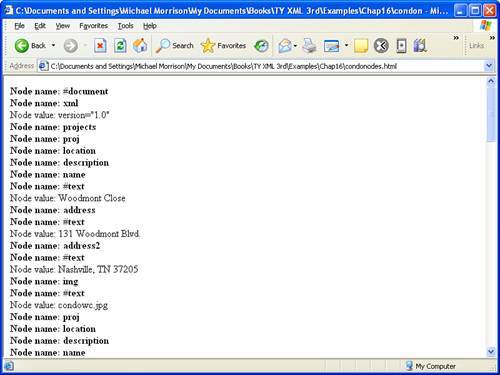
It's worth mentioning that recursion is both a powerful and dangerous programming technique. It's not difficult at all to accidentally create a recursive function that calls itself repeatedly and never stops. You should exercise great care when writing recursive functions. Having said that, recursive functions can be very valuable when processing tree-like structures such as XML documents.
This example is based on the condos.xml document from the previous tutorial, which is partially shown in Listing 16.4.
Listing 16.4. The condos.xml Example XML Document
1: <?xml version="1.0"?> 2: 3: <projects> 4: <proj status="active"> 5: <location lat="36.122238" long="-86.845028" /> 6: <description> 7: <name>Woodmont Close</name> 8: <address>131 Woodmont Blvd.</address> 9: <address2>Nashville, TN 37205</address2> 10: <img>condowc.jpg</img> 11: </description> 12: </proj> 13: <proj status="active"> 14: <location lat="36.101232" long="-86.820759" /> 15: <description> 16: <name>Village Hall</name> 17: <address>2140 Hobbs Rd.</address> 18: <address2>Nashville, TN 37215</address2> 19: <img>condovh.jpg</img> 20: </description> 21: </proj> 22: ... 23: <proj status="completed"> 24: <location lat="36.091559" long="-86.832686" /> 25: <description> 26: <name>Harding Hall</name> 27: <address>2120 Harding Pl.</address> 28: <address2>Nashville, TN 37215</address2> 29: <img>condohh.jpg</img> 30: </description> 31: </proj> 32: </projects>
Hopefully this code allows you to make sense of the output shown in Figure 16.3. For example, the printed XML data that is partially visible in the figure corresponds to the first project in the condos.xml document, which appears in lines 4 through 12.