A Web-based system is of necessity structured in pieces, since it almost never makes sense to put all the work on the client and send everything to it. A Web-based system always has to be aware of the network and scalability. A Web-based system also needs to be as stateless and disconnected as it can get away with. This sounds very client/server-like.
If we are going to consider component-based distributed systems now, we should make a few basic decisions:
Where to put the data access code?
The tiered architecture includes a Data Services tier. Often this is taken to be the database or data source itself, but TMS would argue that this tier also includes the data access code, which acts as the interface to the system's data sources. Consider the options.
Every business object class implements its own data access code. This may be the same code in many places, which is a maintenance problem. Or if there are many disparate data sources, there is a lack of consistency.
However, the bulk of data access code, regardless of its data storage format, is likely to provide the same service, and thus provide the same interface. Imagine the advantages of uniformity: all business objects in the same system, regardless of their business rules, using the same data access interface. Thus there is uniformity for the creation of all generic business services (Create, Read, Update, Delete-the timeless CRUD matrix). This makes it possible to write wizards and add-ins in Visual Basic that generate business objects and all of their common functionality. Since there can be many such business object classes in a system, this can represent a major saving to the project. If a template for the data access class that the business object classes use is created, the internals of supporting different end data sources can be encapsulated behind a standard interface, protecting the business objects from changes of data source, and protecting the data access code from changes of business rule. If data access is provided by a specialized class, this also makes it possible for that class to be bundled as a separate component, which will allow the logical tiers to be physically deployed in any combination. This can have scalability advantages.
The responsibility of the data access service becomes to interface to all supported data sources in as efficient a way as possible and to provide a common interface to any data service consumers. This allows a developer to wrap up RDO or ADO code in a very simple, common interface, but to make the internal implementation as specific, complex, and arcane as performance demands. Such code is also reusable across all projects that use a given type of data source-a handy component to have in the locker if implemented internally in RDO (because it should work with any ODBC compliant data source), and even more generic if it uses ADO internally. But again, as new unique data sources are required, either new implementations of the component (which have new internal implementations but support the same public interface) can be produced or else extra interfaces or parameter-driven switches can be used to aim at other types of data source.
Essentially, when a request for data or a request to modify data comes in to a business object, (for example, "Move all of Account Manager Dante's Customers to Smolensky") probably via a method call from an action object in a Visual Basic front-end program. The business object's method should find the SQL string (or other Data Manipulation Language [DML] syntax) that correspondsto the task required. Once the business object has obtained the SQL string "Update Clients Set Account_Manager_ID = ? where Account_Manager_ID = ?" (or more likely the name of a stored procedure which does this), it passes this and the front-end supplied parameters 12 and 32 to an instance of a DAO object. The DAO object would choose to link with the data source using ADO/RDO, and depending on the format of the DML, it might also convert its data type. The DAO object would then update the data in the remote RDBMS, and pass back a "successful" notification to the business object (its client).
This gives a preferred application structure, as shown in Figure 12-2:
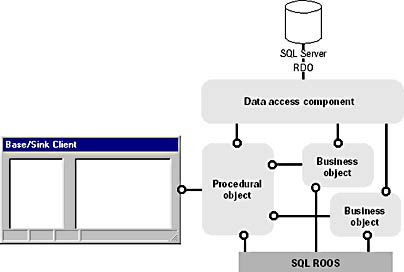
Figure 12-2 Where to put data access code
The Client creates a reference to a procedural object and calls a method on it. In order to carry out the work of that method, the procedural object needs to call more than one business object in a transaction. To do this it creates a reference to a Data Access component, perhaps in its Class_Initialize. It tells the data access component via a method or property that it wants to start a transaction. Then it creates references to each of the business objects and passes the data access component reference to each of them. The procedural object also maintains its own reference to the data access component's object. This is so that they will use the same connection, and thus be in the same transactional context with the database. The business objects carry out their interactions with the database via the same data access component and thus the same database transaction. Once the business objects have finished with the data access component they should set it to nothing. In order to do this, in their Class_Terminate event the business objects must check to see that they have a live reference, and when they find one, setting it to nothing.
The procedural object can now (perhaps in its Class_Terminate) commit the transaction (if no errors have occurred) and set the data access object's reference to nothing, effectively closing it down. This is the "Do it once, do it right, and forget it forever" principle in action.