Introducing Relational Databases
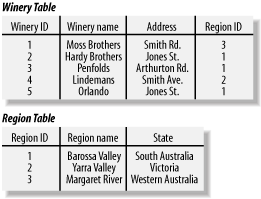
An example relational database is shown in Figure 3-1. This database stores data about wineries and the wine regions they are located in. A relational database manages data in tables, and there are two tables in this example: a winery table that manages wineries, and a region table that manages information about wine regions.
Figure 3-1. An example relational database containing two related tables
Databases are managed by a relational database management system (RDBMS). An RDBMS supports a database language to create and delete databases and to manage and search data. The database language used in almost all DBMSs is SQL, a set of statements that define and manipulate data. After creating a database, the most common SQL statements used are INSERT, UPDATE, DELETE, and SELECT, which add, change, remove, and search data in a database, respectively.
A database table may have multiple columns, or attributes, each of which has a name. For example, the winery table in Figure 3-1 has four attributes, winery ID, winery name, address, and region ID. A table contains the data as rows or records, and a row contains attribute values. The winery table has five rows, one for each winery managed by the database, and each row has a set of values. For example, the first winery has a winery ID value of 1, the winery name value Moss Brothers, and an address of Smith Rd., and is situated in the region ID numbered 3. Region 3 is a row in the region table and is Margaret River in Western Australia.
The relationship between wineries and regions is maintained by assigning a region ID to each winery row. Managing relationships in this way is fundamental to relational database technology, and different types of relationship can be maintained. In this example, more than one winery can be situated in a region-three wineries in the example are situated in the Barossa Valley-but a winery can be situated in only one region.
Attributes have data types. For example, in the winery table, the winery ID is an integer, the winery name and address are strings, and the region ID is an integer. Data types are assigned when a database is designed.
Tables usually have a primary key, which is one or more values that uniquely identify each row in a table. The primary key of the winery table is winery ID, and the primary key of the region table is region ID. Primary keys are usually indexed to provide fast access to rows when they are searched by the primary key value. For example, an index is used to find the details of the region row that matches a given region ID in a winery table row.
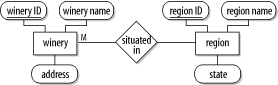
Figure 3-2 shows the example database modeled using entity-relationship (ER) modeling. The winery and region tables or entities are shown as rectangles. Each entity has attributes, and the primary key is shown underlined. The relationship between the tables is shown as a diamond that connects the two tables, and in this example the relationship is annotated with an M at the winery-end of the relationship. The M indicates that there are potentially many winery rows associated with each region. Because the relationship isn't annotated at the other end, this means that there is only one region associated with each winery. ER modeling is discussed in more detail in Appendix C.
Figure 3-2. An example relational model of the winery database